Fast-forward 80 or so years from the publication of
On Growth and Form in 1917 to the mid-1990’s, pausing for a brief nod to the stunning accomplishments of molecular biology in the last half of the 20th century. These include, first and foremost, the unraveling of the structure of DNA, with its moment of drama unmatched in the history of science, so well described in Horace Judson’s
8th Day of Creation, when the structure suddenly fell into place like a jigsaw puzzle. “We have discovered the secret of life” they told the waiter at the
Eagle pub. The discovery was an announced to the world in a 1 page
paper legendary for both its brevity and its understated conclusion: “It has not escaped our notice that the specific pairing we have postulated immediately suggests a possible copying mechanism for the genetic material.”.
Their discovery launched a decade or so of working out the genetic code and the machinery of what has become known as the
Central Dogma of molecular biology: DNA makes DNA, and also DNA makes (messenger) RNA, which makes proteins, which drive the symphony of organized chemistry we call life. These insights launched a thousand successive revolutions both pure and applied, including
recombinant DNA technology, the biotechnology industry,
“biologic” drugs (i.e., therapeutic proteins),
gene therapy (not yet ready for prime time), and the era of
genome sequencing epitomized by, but by no means limited to, the
sequencing of the human genome. The simplicity of the central dogma has been under assault in the last decade, as
RNA has refused to be content with the
messenger role assigned to it, and has been laying claim to previously unsuspected new functions, from
chemical catalysis to
gene regulation. But I am getting ahead of myself. By the mid-1990’s the central dogma was settled, a couple of decades of painstaking piecemeal sequencing of isolated genes had passed, and
high throughput sequencing was ramping up, so that one knew that it was a matter of time before complete gene lists for organisms would start to become available.
Genes were (are) thought to be the atomic statements, the single lines of code, in the organismal program. People’s thoughts were turning increasingly to gene regulation, the mechanism which tells a cell which genes to turn on when, and hence which proteins to make. Gene regulation itself was not a new concept; it has its own august history going back to the pioneering work of Jacob and Monod in the early 1960’s with the unraveling of the
first bacterial operon. However, with the industrialization of sequencing bringing with it the prospect of complete knowledge of genome sequence, the possibility of a complete understanding of gene regulatory programs was now starting to become less far-fetched.
With that setting of the historical stage, I want to turn to a 1996 paper in the journal
Development by
Eric Davidson and his student
Chiow Hwa Yuh entitled
Modular cis-regulatory organization of Endo16, a gut-specific gene of the sea urchin embryo . Davidson, a professor of developmental biology at CalTech, had by this time spent several decades studying the early development of the sea urchin. Why the sea urchin, you might ask? Well, since you asked, allow me one more digression on the subject of
model organisms. While much biological research is justified in grant proposals by its potential impact on practical goals like advancing human health or agricultural productivity, it turns out that people and corn, respectively, are often not the most convenient organisms to do experiments in. The factors that make an organism convenient for experimentation include ease and cost of propagation in a laboratory, a short generation time to allow the effects of mutations or developmental perturbations to be observed quickly, and experimental tractability, which means a toolkit of methods and resources for tweaking the normal biology, usually amassed over a generation or two of research by a community of scientists focused on an organism. The worst possible organism for doing biology on is Homo sapiens: long generation time, tons of ethical restrictions on what sorts of experiments you can do, expensive to maintain, etc. In the plant world, the organisms we care most about, crops and trees, have generation times ranging from once per season for corn (2-3 generations per year if you are willing to switch back and forth between the northern and southern hemisphere, like agribusiness giants like Monsanto and DuPont/Pioneer), and once or twice per decade, for trees. Fortunately, a lot of biology is conserved across organisms, and you can learn a lot that is relevant to humans from studying organisms as far afield as
yeast, which shares with us much fundamental machinery of cell division, to invertebrates like the
sea urchin, the
nematode worm or the
fruitfly, which share with us many signaling, regulatory and developmental pathways, to nonmammalian vertebrates like the
zebrafish, which shares many of our cell types and anatomical structures but has the tremendous advantage of being transparent, and closest to home, the mammalian model of choice, the
mouse. For physiological research the
rat enjoys some popularity, and
dogs show considerable promise for teaching us about the genetics of behavior, but for molecular biology of development in mammals, the mouse is as good as it gets: fast, cheap and versatile. In the plant world the role of the mouse is played by the small, mustard-like weed
Arapidopsis thaliana, extensively studied by plant geneticists, and the first plant to have its genome sequenced. The idea of having a simplified version of a complex system which can be more easily studied would seem to be fairly obvious, except that every few years some
astonishingly ignorant politician will grab some
headlines by complaining about taxpayer money being wasted on the study of fruitflies.
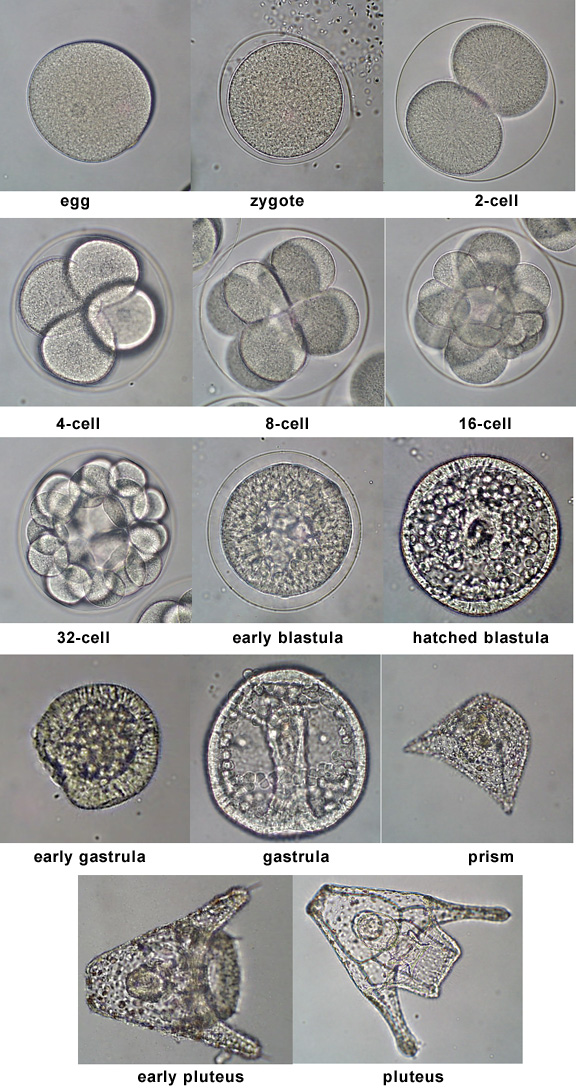
So: sea urchins. Like most multicellular organisms, they develop from a single cell. They go through early
2,4,8,… cell
cleavages, passing through morula (raspberry),
blastula (hollow ball) and
gastrula (folded ball) phases of development similar to many other animal species, including ourselves. They are convenient: you can
gather lots of fertilized eggs easily and watch them develop, or interfere. Davidson's lab studies the genetics of sea urchin development.
The aforementioned 1996 paper presented a detailed model to explain the regulation of a
single gene expressed in a particular tissue in a sea urchin embryo. The question was why there and then? One way genes are known to be regulated is via their
promoters: DNA regions just upstream from the protein-coding part of the gene. Special proteins called
transcription factors can recognize specific DNA sequences in the promoters of particular genes and bind to them; in so doing they can activate or repress the transcription of mRNA messages from that gene, which in one step in the chain leading to the manufacture of that gene's protein product. Different transcription factors recognize sequences in front of different genes, leading to a network of activation and repression relationships between genes and their protein products.
Yuh and Davidson's paper tried to work out a detailed model for the regulation of one gene: which transcription factors bound to its promoter and what the effect was. They had to do a lot of
promoter bashing experiments to work this out. What was unusual about their paper was ttheir attempt to produce a complete, quasi-mathematical description of the activation conditions for the gene. They concluded that it was not enough to specify purely Boolean on/off conditions for the gene, although some of the transcription factors did have this kind of effect. Others had a more graded effect, with more bound proteins producing more gene expression.
You can see a summary
here.

Above: a figure from the paper. See also a calculator to compute the model's output expression level under different conditions.
What was striking about their model was, first, how complex the regulation of one gene in one humble organism could be, but also the images suggested that the networks of gene regulation, while complex, might be amenable to the same sorts of diagrams and mathematics that electrical engineers use to make sense of complex circuits. In subsequent years Davidson and collaborators extended their models to include other genes, pathways, and species, and developed a set of diagramming conventions and tools for genetic regulatory networks (GRNs). Davidson later wrote Genomic Regulatory Systems

which is a manifesto for the unravelling of the regulatory networks of organisms. The GRN diagrams have been applied to a number of other species and systems. They have also grown considerably more complex:

From a Thompsonian perspective, this thread of work is incomplete in one crucial way. Although it provides a way of thinking about the control of genes, the work to date, to my knowledge, does not make the link to form. We still lack the simulator that can take the above diagram and compute a video of a developing sea-urchin embryo as output. That is no criticism of the work of Davidson and colleagues, who have taken us a huge step in that direction. Just an observation that there is a ways yet to go.
 Shemeck early computer graphic work was published in a book, the Algorithmic Beauty of Plants, that is a classic in the field of e-morphogenetics: perhaps its only coffee-table book to date. The book is now freely available in electronic form at Algorithmic Botany, the web site for Shemeck's lab, along with more recent images and publications. The web-site also has Quick-Time animations that show the temporal behavior of these models. Although at first the focus of the work was primarily on producing realistic plant graphics without much concern for biological realism, over time more biology was layered on: for example, plant hormones emmited in one part of the plant and sensed in another to trigger flowering. The modeling was mostly at the level of structural elements like leaves and branches, as opposed to cells or genes. However chapter 7 describes some explorations in the application of L-system graphics to 2 and 3-dimensional systems of cells; some examples are show below.
Shemeck early computer graphic work was published in a book, the Algorithmic Beauty of Plants, that is a classic in the field of e-morphogenetics: perhaps its only coffee-table book to date. The book is now freely available in electronic form at Algorithmic Botany, the web site for Shemeck's lab, along with more recent images and publications. The web-site also has Quick-Time animations that show the temporal behavior of these models. Although at first the focus of the work was primarily on producing realistic plant graphics without much concern for biological realism, over time more biology was layered on: for example, plant hormones emmited in one part of the plant and sensed in another to trigger flowering. The modeling was mostly at the level of structural elements like leaves and branches, as opposed to cells or genes. However chapter 7 describes some explorations in the application of L-system graphics to 2 and 3-dimensional systems of cells; some examples are show below. Shemeck early computer graphic work was published in a book, the Algorithmic Beauty of Plants, that is a classic in the field of e-morphogenetics: perhaps its only coffee-table book to date. The book is now freely available in electronic form at Algorithmic Botany, the web site for Shemeck's lab, along with more recent images and publications. The web-site also has Quick-Time animations that show the temporal behavior of these models. Although at first the focus of the work was primarily on producing realistic plant graphics without much concern for biological realism, over time more biology was layered on: for example, plant hormones emmited in one part of the plant and sensed in another to trigger flowering. The modeling was mostly at the level of structural elements like leaves and branches, as opposed to cells or genes. However chapter 7 describes some explorations in the application of L-system graphics to 2 and 3-dimensional systems of cells; some examples are show below.
Shemeck early computer graphic work was published in a book, the Algorithmic Beauty of Plants, that is a classic in the field of e-morphogenetics: perhaps its only coffee-table book to date. The book is now freely available in electronic form at Algorithmic Botany, the web site for Shemeck's lab, along with more recent images and publications. The web-site also has Quick-Time animations that show the temporal behavior of these models. Although at first the focus of the work was primarily on producing realistic plant graphics without much concern for biological realism, over time more biology was layered on: for example, plant hormones emmited in one part of the plant and sensed in another to trigger flowering. The modeling was mostly at the level of structural elements like leaves and branches, as opposed to cells or genes. However chapter 7 describes some explorations in the application of L-system graphics to 2 and 3-dimensional systems of cells; some examples are show below.












 The question elegantly posed by these images is: how does nature transform organism shapes in the course of evolution? This question depends on a still more basic one: how does nature generate organism forms in the first place? These questions are, respectively, the
The question elegantly posed by these images is: how does nature transform organism shapes in the course of evolution? This question depends on a still more basic one: how does nature generate organism forms in the first place? These questions are, respectively, the {kind=link}
{kind=link}
{kind=link}